Scraping OpenLearn
Contents
Scraping OpenLearn#
This section describes how we can obtain a list of free OpenLearn units and construct a database that provides a full-text search over the unit names and originating course codes for those units. It also demonstrates how we can populate the database with copies of the OU-XML documents associated with those units and trivially query those documents as parsed XML documents using XPATH expressions. Examples are also given of how we can download and inspect zipped HTML bundles associated with free OpenLearn units, extract “contentful” image files into a database, and then retrieve and preview those images.
Getting a List of OpenLearn Units#
In previous years, OpenLearn used to publish an OPML feed that list all the units available on OpenLearn. The feed included the unit name, the module code for the original OU module from which the OpenLearn unit was derived, and a link to unit homepage on OpenLearn.
That feed is no longer available, but a single HTML page listing all the free units is still available at https://www.open.edu/openlearn/free-courses/full-catalogue
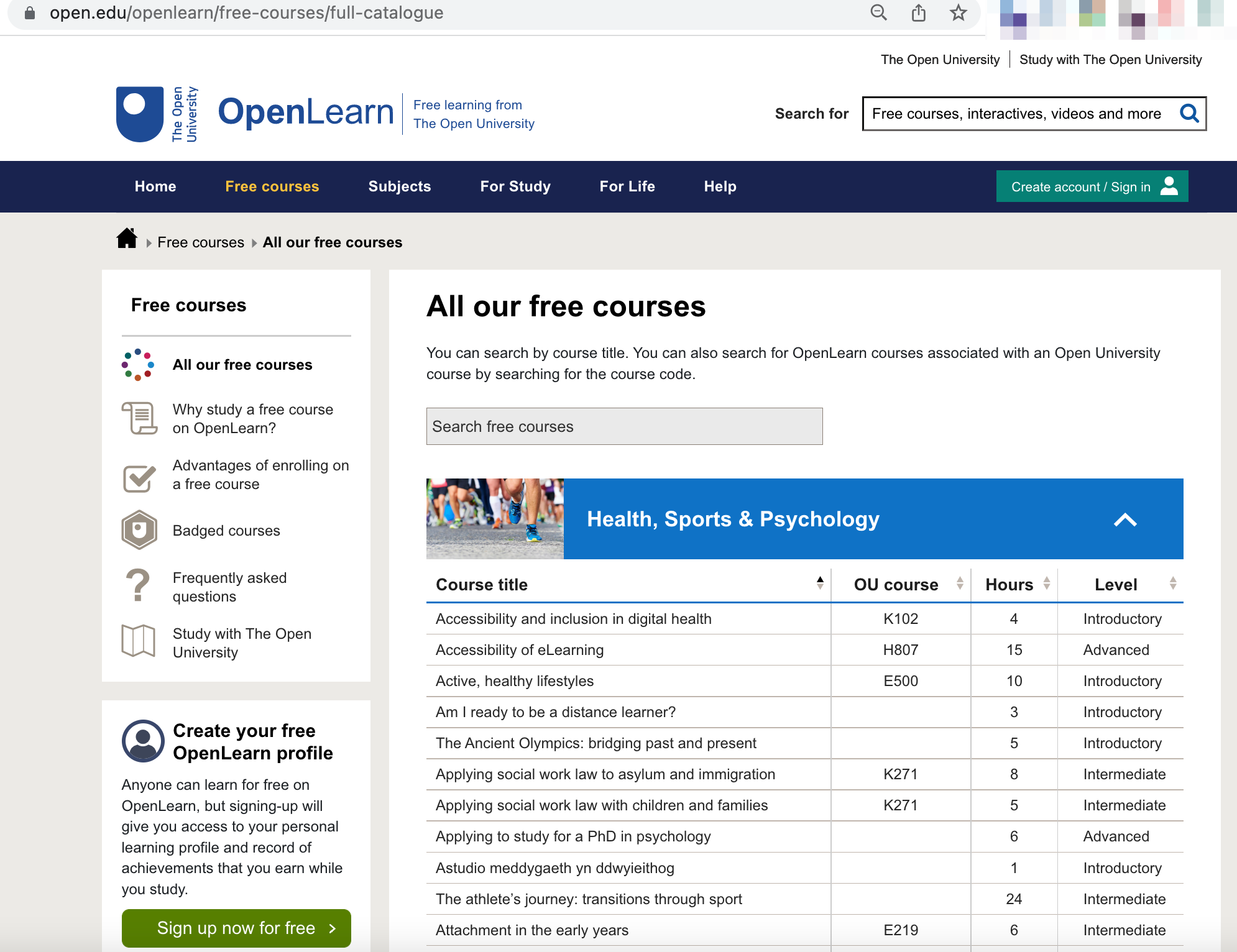
The units are listed within an HTML table, one unit per row, with the following structure:
<table>
...
<tr class="even">
<td class="views-field views-field-title active views-align-left title"
data-sort-value="visions of protest: graffiti">
<a href="https://www.open.edu/openlearn/history-the-arts/visions-protest-graffiti/content-section-0">Visions of protest: graffiti</a>
<span class="hidden"> Y031</span>
</td>
<td class="views-field views-field-field-ou-course views-align-center
field_ou-course" data-sort-value="Y031">
Y031
</td>
<td class="views-field views-field-field-duration views-align-center field_duration"
data-sort-value="8">
8
</td>
<td class="views-field views-field-field-educational-level views-align-left field_educational_level"
data-sort-value="Introductory">
Introductory
</td>
</tr>
...
</table>
Scraping the List of Free OpenLearn Units#
From the HTML table that lists all the free units available on OpenLearn, we can grab a list of the unit names, duration, level, original OU module and the OpenLearn unit URL.
We can also generate candidate URLs for the OU-XML and HTML zip downloads. These URLs are conventionally defined, but the resources are not necessarily published there. Having generated the URL, we can make a simple HTTP/HEAD request to see whether a resource is actually available at the URL (if the resource is available, we get a 200/OK message; if the resource is not available, we get a 404/Page not found).
# The requests package provides a range of utilities for
# making http calls, retrieving html pages etc
import requests
# If appropriate, we can cache http requests made using the requests package
import requests_cache
requests_cache.install_cache('openlearn_cache')
# Suspend with with requests_cache.disabled():
# The BeuatifulSoup package provides a range of tools for parsing
# HTML documents and scraping elements from them
from bs4 import BeautifulSoup
# We can use the tqdm package to provide progress bar indicators
# that allow us to keep track of the state of progress of a scrape
# of multiple pages
from tqdm.notebook import tqdm
Our scrape begins by grabbing the HTML page for the free unit catalogue and extracting the table that contains the unit listings:
# URL for the OpenLearn full catalogue of free units
srcUrl='https://www.open.edu/openlearn/free-courses/full-catalogue'
# Grab the HTML page
html = requests.get(srcUrl).content
# Creating a soup object (a navigable tree element)
soup = BeautifulSoup(html, 'html.parser')
# The table containing the listing is found within a div element
# with a particular, unique id
table = soup.find("div", {"id": "expander_content_11"}).find("table")
For each row in the table, except from the header row, we can extract the OpenLearn unit name and homepage URL, and the level, anticipated duration, and parent OU module code, if available. We can also derive conventional URLs for the OU-XML and HTML zip downloads, and make HTTP/HEAD requests to poll to see whether those assets actually exist at the conventional location.
# We're going to build up a list of dicts, one dict per unit
units = []
# The first row of the table is a header row
# so we can skip it
for row in tqdm(table.find_all("tr")[1:]):
# Get the url for each OpenLearn unit homepage
url = xmlurl = htmlurl = row.find("a").get("href")
# Get the unit name, parent OU module code, level and time allocation
name = row.find("a").text.strip()
code = row.find("span", {"class":"hidden"}).text.strip()
level = row.find("td", {"class":"field_educational_level"})
duration = row.find("td", {"class":"field_duration"})
# Simple cleaning
level = level.text.strip() if level else level
duration = duration.text.strip() if duration else duration
# Do a simple header check to see if the ou-xml and html downloads
# are available at the conventional location
# We could look at the full homepage for download element links
# but that means actually loading each unit page, rather than just
# performing a header check
for stub in ["content-section-overview", "content-section-0" ]:
xmlurl = xmlurl.replace(stub, "altformat-ouxml")
htmlurl = htmlurl.replace(stub, "altformat-html")
xmlurl = xmlurl if "altformat-ouxml" in xmlurl and requests.head(xmlurl).status_code==200 else None
htmlurl = htmlurl if "altformat-html" in htmlurl and requests.head(htmlurl).status_code==200 else None
# Build up a list of dicts, one dict per unit on OpenLearn
units.append({"name": name,
"code": code,
"level": level,
"duration": int(duration),
"url": url,
"xmlurl": xmlurl,
"htmlurl": htmlurl
}
)
Preview the results of the scrape:
units[:3]
[{'name': 'A brief history of communication: hieroglyphics to emojis',
'code': 'L101',
'level': 'Introductory',
'duration': 5,
'url': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/content-section-0',
'xmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-ouxml',
'htmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-html'},
{'name': 'Academi Arian MSE',
'code': '',
'level': 'Introductory',
'duration': 12,
'url': 'https://www.open.edu/openlearn/money-business/academi-arian-mse/content-section-overview',
'xmlurl': None,
'htmlurl': None},
{'name': 'Accessibility of eLearning',
'code': 'H807',
'level': 'Advanced',
'duration': 15,
'url': 'https://www.open.edu/openlearn/education-development/education-careers/accessibility-elearning/content-section-0',
'xmlurl': 'https://www.open.edu/openlearn/education-development/education-careers/accessibility-elearning/altformat-ouxml',
'htmlurl': 'https://www.open.edu/openlearn/education-development/education-careers/accessibility-elearning/altformat-html'}]
We can add the list of units to a simple database table using the file based SQLite database.
# The sqlite_utils package provides a wide range of tools
# that support working with SQLite databases
from sqlite_utils import Database
# The database will be saved to a file
dbname = "all_openlean_xml.db"
# If necessary, provide a clean start
#!rm -f $dbname
# Create a database connection
# This creates the database file if it does not already exist
# otherwise we connect to a pre-existing database file
db = Database(dbname)
We can create a database table structure on the fly simply by inserting documents into it, or we can create a database table schema in advance. We can also create a secondary table that supports full-text search and that will be dynamically updated whenever we add a record to the table we want to provide full-text search over.
# Create a new table reference (units)
all_units = db["units"]
# Clear the table to give us a fresh start
# Setting ignore=True prevents an error if the table does not exist
all_units.drop(ignore=True)
# Define the table structure
all_units.create({
"code": int,
"name": str,
"level": str,
"duration": int,
"url": str,
"xmlurl": str,
"htmlurl": str,
"id": str
}, pk=("id"))
# Ideally, we would take the id as a unique ID from inside
# an OU-XML document. Alternatively, we might generate one,
# for example as an md5 hash of unique (name, code) pairs.
# We can improve search over the table by supporting full-text search.
# This involves the creation of a secondary table with a full-text search
# index provided over one or more specified columns.
# The full-text search table is automatically updated whenever one or more
# items are added to the table with which the search index is associated.
db[f"{all_units.name}_fts"].drop(ignore=True)
# If we add the id to the index, we can trivially reference into the
# table from the full-text search result.
# The id should ideally not be anything you are likely to search on...
all_units.enable_fts(["name", "code", "id"], create_triggers=True)
<Table units (code, name, level, duration, url, xmlurl, htmlurl, id)>
Let’s create a simple function to create a unique identifier for each of our units:
import hashlib
def create_id(records, id_field="id", fields=["code", "name"]):
"""Create a key from the specified fields."""
fields = [fields] if isinstance(fields, str) else fields
for record in records:
key = "-".join([record[k] for k in fields ])
# We could check there is no collision on the id key
record[id_field] = hashlib.sha1(key.encode(encoding='UTF-8')).hexdigest()
# The dict is updated directly so we have no return value
We can now add our list of units to the units table in the database (the full-text search table will be automatically updated):
create_id(units)
units[:1]
[{'name': 'A brief history of communication: hieroglyphics to emojis',
'code': 'L101',
'level': 'Introductory',
'duration': 5,
'url': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/content-section-0',
'xmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-ouxml',
'htmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-html',
'id': '1f194525072f4358f7639c471ee5289665d50a3f'}]
all_units.insert_all(units)
<Table units (code, name, level, duration, url, xmlurl, htmlurl, id)>
Let’s try a test query, pulling the results back into a pandas dataframe for convenience:
import pandas as pd
pd.read_sql("SELECT * FROM units LIMIT 3", con=db.conn)
| code | name | level | duration | url | xmlurl | htmlurl | id | |
|---|---|---|---|---|---|---|---|---|
| 0 | L101 | A brief history of communication: hieroglyphic... | Introductory | 5 | https://www.open.edu/openlearn/languages/a-bri... | https://www.open.edu/openlearn/languages/a-bri... | https://www.open.edu/openlearn/languages/a-bri... | 1f194525072f4358f7639c471ee5289665d50a3f |
| 1 | Academi Arian MSE | Introductory | 12 | https://www.open.edu/openlearn/money-business/... | None | None | 08e64f95154b120c346a169c820a12f8ce17a182 | |
| 2 | H807 | Accessibility of eLearning | Advanced | 15 | https://www.open.edu/openlearn/education-devel... | https://www.open.edu/openlearn/education-devel... | https://www.open.edu/openlearn/education-devel... | 78aec27976cb7d1ce356bf0eda6e8fb66ea532e9 |
We can also try a full-text search:
# full-text search term(s)
# This may include boolean search operators
q = "history communication OR H807"
# Construct a query onto the full-text search index
_q = f"""
SELECT * FROM units_fts WHERE units_fts MATCH {db.quote(q)} ;
"""
pd.read_sql(_q, con=db.conn)
| name | code | id | |
|---|---|---|---|
| 0 | A brief history of communication: hieroglyphic... | L101 | 1f194525072f4358f7639c471ee5289665d50a3f |
| 1 | Accessibility of eLearning | H807 | 78aec27976cb7d1ce356bf0eda6e8fb66ea532e9 |
Building a Database of OU-XML Documents#
From the list of free units on OpenLearn, we constructed the URL for the OU-XML download associated with the unit and polled the OpenLearn website to check whether the resource exisited. Only OU-XML URLs that refer to an actually downloadable resource were then added to our units list, and to the database.
We can now create a further table into which we will insert the OU-XML document (where available) associated with each OpenLearn unit.
If the units list is not available, we could query the units database table for units where the OU-XML URL exists, and then use that list to download the referenced OU-XML resources and add them to our database.
To support discovery, we can also make the XML document full-text searchable. Whilst this means the index will be cluttered with XML tags and tags conjoined with words they abut, most of the content will be indexed appropriately.
all_xml_tbl = db["xml"]
all_xml_tbl.drop(ignore=True)
all_xml_tbl.create({
"code": int,
"name": str,
"xml": str,
"id": str
}, pk=("id"), if_not_exists=True)
db[f"{all_xml_tbl.name}_fts"].drop(ignore=True)
all_xml_tbl.enable_fts(["xml", "id"], create_triggers=True)
<Table xml (code, name, xml, id)>
Let’s grab all the files, again using a tqdm progress bar to help us keep track of how much progress we have made.
To optimise things a little, only try to grab units where we know there is an OU-XML resource available.
# The following construction is known as a list comprehension
# We construct a new list from the units list containing only
# units where the OU-XML url (u["xmlurl"]) exists
_units = [{"code": u["code"], "name":u["name"],
"xmlurl": u["xmlurl"]} for u in units if u["xmlurl"]]
# Create a unique key for each record
create_id(_units)
# For each unit with an ouxml URL, get the OU-XML resource
# and add it to the database
for u in tqdm( _units ):
u["xml"] = requests.get(u["xmlurl"]).content
del u["xmlurl"]
all_xml_tbl.insert(u)
_units = [{"code": u["code"], "name":u["name"],
"xmlurl": u["xmlurl"]} for u in units if u["xmlurl"]]
Let’s preview what we’ve got:
pd.read_sql("SELECT * FROM xml LIMIT 3", con=db.conn)
| code | name | xml | id | |
|---|---|---|---|---|
| 0 | L101 | A brief history of communication: hieroglyphic... | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 1f194525072f4358f7639c471ee5289665d50a3f |
| 1 | H807 | Accessibility of eLearning | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 78aec27976cb7d1ce356bf0eda6e8fb66ea532e9 |
| 2 | Addysg gynhwysol: deall yr hyn a olygwn (Cymru) | b'<?xml version="1.0" encoding="UTF-8"?>\n<Ite... | 394a675903e951ecef13496f1dc59769b300d170 |
We can also search across the unit name, or search into the XML document, albeit in an unstructured way:
pd.read_sql("SELECT * FROM xml WHERE xml LIKE '%Egyptian%' LIMIT 3", con=db.conn)
| code | name | xml | id | |
|---|---|---|---|---|
| 0 | L101 | A brief history of communication: hieroglyphic... | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 1f194525072f4358f7639c471ee5289665d50a3f |
| 1 | GA060 | Art and life in ancient Egypt | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | df0a67eeda24c3e3f29f5d70c67b9cf218003929 |
| 2 | AA315 | Art in Renaissance Venice | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 5d12fb13f9ba7bcc3bb04d066220d6be5fbe8884 |
Free text search over the associated full-text search table is also available.
Let’s create a simple function to help with that:
def fts(db, base_tbl, q):
"""Run a simple full-text search query
over a table with an FTS virtual table."""
_q = f"""SELECT * FROM {base_tbl}_fts
WHERE {base_tbl}_fts MATCH {db.quote(q)} ;"""
return pd.read_sql(_q, con=db.conn)
We can now run a full-text search without having to rememeber the query syntax:
fts(db, "xml", "quantum light physics")
| xml | id | |
|---|---|---|
| 0 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 3bfc64d5fe351c3ae8f0adf78fab77b0abe01899 |
| 1 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | b606a83711e00553c315a684c6805a3344751691 |
| 2 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 884164a46f4066c6b26894c812484c74ab2e8531 |
| 3 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | f36ae6f445e1c39925fa84d3e188af9ed7c15fdc |
| 4 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 9cb30f7891ecc70f55bac61a991066f8bb5d775c |
| 5 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 84fea7b4cf86cdd4e31e3272572372972fb81fe2 |
| 6 | b'<?xml version="1.0" encoding="UTF-8"?>\n<Ite... | c2c90459369d82e28e768dfd9072047eab95be4d |
| 7 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | fa29090cabd04174ca4bd4c8ea4310d33df9b9c4 |
| 8 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 4095122554b7cc3cff824f31c3cf531087e63b2c |
| 9 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | b627720e439b6721911399de37a34f3b8e510c75 |
| 10 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 28b6aa9ae28ff352cb22fbf3391046948e9aefe2 |
| 11 | b'<?xml version="1.0" encoding="UTF-8"?>\n<?sc... | 75a013ae7e703481e8f0e05bde38d6d71fa732b6 |
| 12 | b'<?xml version="1.0" encoding="utf-8"?>\n<?sc... | 1f41fd69fb50ec76b9296c52f26d54b135067c4e |
Retrieving and Working With OU-XML Stored in the Database#
We can now grab an OU-XML document from our database, parse it into an XML object:
from lxml import etree
# Grab the XML from the database for a particular module
# (If there are several units derived from the module,
# use the first in the results list)
h807_xml_raw = pd.read_sql("SELECT xml FROM xml WHERE code='H807'", con=db.conn).loc[0, "xml"]
# Parse the XML into an xml object
root = etree.fromstring(h807_xml_raw)
root
<Element Item at 0x7fbb30e8bd00>
We can now run a simple XPATH query directly over the parsed XML object:
# Use xpath expressions to navigate to particular elements
# in the XML document object
# Select the first ItemTitle element and render its text content
root.xpath("ItemTitle")[0].text
'Accessibility of eLearning'
We can also query deeper into the document, and render the structure of a particular element. The following convenience function will return the raw XML in binary or string form associated with a particular XML document node element:
def unpack(x, as_str=False):
"""Convenience function to look at the structure of an XML object."""
return etree.tostring(x) if not as_str else etree.tostring(x).decode()
Let’s see what we get if we view the <LearningOutomes> element:
print( unpack( root.xpath("//LearningOutcomes")[0], as_str=True))
<LearningOutcomes xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Paragraph>After studying this course, you should be able to:</Paragraph>
<LearningOutcome>discuss the main challenges facing disabled students with respect to eLearning.</LearningOutcome>
<LearningOutcome>have an understanding of the types of technology used by disabled students.</LearningOutcome>
<LearningOutcome>consider what adjustments you might make in creating eLearning materials to ensure they are accessible and usable.</LearningOutcome>
<LearningOutcome>consider appropriate ways to evaluate the accessibility and usability of your eLearning materials. </LearningOutcome>
</LearningOutcomes>
If we ever need to do maintenance on the datbase, for example purging deleted tables, we can run a cleaning operation over it:
# Tidy up a database to improve its efficiency
db.vacuum()
Scraping and Storing HTML Media Assets#
The easiest way to grab the media assets associated with each unit is probably to download the HTML bundle.
To be most useful, this means we need to be able to reconcile the downloaded assets with the media assets referenced in the corresponding OU-XML document.
Rather than download all the media assets for all the free OpenLearn units, we will limit ourselves to a simple proof of concept that just downloads the assets associated with a single OpenLearn model.
We will leave the question of how to reconcile the assets with the assets referenced in the corresponding OU-XML document till another time. However, we will show how we can work with downloaded media assets that have been saved into our database.
To start with, let’s find a unit for which we have an
# Get the list of units where there's an html URL and take the first
# We could of course also query our database to fin one...
example_unit = [u for u in units if u["htmlurl"]][0]
example_unit
{'name': 'A brief history of communication: hieroglyphics to emojis',
'code': 'L101',
'level': 'Introductory',
'duration': 5,
'url': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/content-section-0',
'xmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-ouxml',
'htmlurl': 'https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-html',
'id': '1f194525072f4358f7639c471ee5289665d50a3f'}
Let’s get the HTML bundle URL, an also extract the unit path name; we can use the latter to name our download file.
# Get the HTML bundle download URL
hurl = example_unit["htmlurl"]
#Get the pathname for the unit
fname = hurl.split('/')[-2]
#Preview these variables
print(f"- hurl: {hurl}\n- fname: {fname}")
- hurl: https://www.open.edu/openlearn/languages/a-brief-history-communication-hieroglyphics-emojis/altformat-html
- fname: a-brief-history-communication-hieroglyphics-emojis
The HTML is is actually a zip file. We can use the urllib.request to download this package to our computer.
import urllib.request
# Create a helper to download the resource for us
getter = urllib.request.URLopener()
# Specify a name for the downloaded file
download_file = f"{fname}.zip"
getter.retrieve(hurl, download_file)
# This is the file we saved the resource as
download_file
'a-brief-history-communication-hieroglyphics-emojis.zip'
We can peek inside the zip archive file using the zipfile package:
import zipfile
# zip file handler
zip_ = zipfile.ZipFile( download_file )
# list available files in the container
zip_.namelist()[30:50]
['Items/x_7_l101_1_4.html',
'Items/x_8_l101_1_4_1.html',
'Items/x_9_l101_1_4_2.html',
'Items/x_l101_1__descriptiond0e321.html',
'Items/x_l101_1__descriptiond0e373.html',
'Items/x_l101_1__descriptiond0e400.html',
'Items/x_l101_1__descriptiond0e425.html',
'Items/x_l101_1__descriptiond0e618.html',
'Items/x_l101_1__descriptiond0e689.html',
'Items/x_l101_1__descriptiond0e868.html',
'Items/x_l101_1__transcriptd0e281.html',
'Items/x_l101_1__transcriptd0e713.html',
'Items/_31fc26135690af3deb1715277799629474e0d87f_l101_2018j_aug037.mp3',
'Items/_36eab0b10aa000c0eb95f4e1477d160bc385d5ce_l101_ol_twitter_emoji.mp4',
'Items/_7230df23b5f8f3060b83c6e99739622f8735350b_l101_ol_218698sumeriancuneiformtabletfig4.tif',
'Items/_81f1f0e2202e38db69792d8252d6dc827058f631_l101_ol186633_fig1emoji_decorative.tif',
'Items/_8a6712fa3ab54067a8165ef97c01bebf9d504e1d_l101_ol_figure9.jpg',
'Items/_9869fc8aa3ffbb0c5ceeceaaeeac7a7a1acf6877_l101_blk1_u4_pt3.eps.jpg',
'Items/_b735beaea648bb1268b74b8b7987f20ae3c0054d_l101_ol_fig3_218696_lascaux_cave_paintings.jpg',
'Items/_cc58a9b2a70b53241285f4ec062c24982e18f253_video1_poster.jpg']
The zip file is organised like a directory: it contains files and subdirectories within it.
The OU-XML content has been rendered into separate HTML files for the different XML sections (for example, Items/x_7_l101_1_4.html). There also seem to be lots of images in the zipfile, not all of which may be “content” images (for example, some images may be logos or navigation icons).
One way of finding out which images are content related is to look through the content HTML documents and extract the image references from them.
The following function takes the path to a downloaded zip file, looks inside it for “contentful” HTML pages, and then attempts to find references to “contentful” figure images.
Note that the HTML bundles for different units may have been generated at different times and may have different internal HTML structure.
def get_imgs_from_html(zip_, zip_fpath):
"""Get a list of image paths and alt text from an HTML file."""
# Open zip file
f = zip_.open(zip_fpath)
# Create a reference to an HTML parser
soup = BeautifulSoup(f, 'html.parser')
# Depending on when the HTML bundle was generated,
# we often find image references in a particularly classed
# div element
figures = soup.find_all("div", {"class": "oucontent-figure"})
fig_list = []
# For each figure reference
for fig in figures:
# Get the local image path
# This path is locally valid in the zipfile context
img_path = fig.find("img").get('src')
fig_list.append(img_path)
return fig_list
If we iterate through what we assume to be the contentful HTML files, we can get a list of references to what we assume are contentful images:
# A list of what we assume to be "contentful images"
images = []
# Get a reference to the zip file
zip_ = zipfile.ZipFile( download_file )
# Iterate through the directories and files in the zip file
# Note that we consume the list as we iterate it,
# so if we want to view the list again we need to recreate
# the zip_ reference
for n in zip_.namelist():
# Assume a "contentful" html file is one on the Items/ path
if n.startswith("Items/") and n.endswith(".html"):
# Grab the image references from the file on that path
_images = get_imgs_from_html(zip_, n)
# Add the list of images from that file to our overall
# list of contentful images
images.extend(_images)
images
['_8a6712fa3ab54067a8165ef97c01bebf9d504e1d_l101_ol_figure9.jpg',
'_ddd79f44c1411de8c1f9689825f45189df1c11f3_l101_fig1_186141gedoenmaheux.jpg',
'_9869fc8aa3ffbb0c5ceeceaaeeac7a7a1acf6877_l101_blk1_u4_pt3.eps.jpg',
'_81f1f0e2202e38db69792d8252d6dc827058f631_l101_ol186633_fig1emoji_decorative.tif',
'_d7b7906d25a1744b217da0673439d17c601eb728_l101_fig2_218416hieroglyphics.tif',
'_b735beaea648bb1268b74b8b7987f20ae3c0054d_l101_ol_fig3_218696_lascaux_cave_paintings.jpg',
'_7230df23b5f8f3060b83c6e99739622f8735350b_l101_ol_218698sumeriancuneiformtabletfig4.tif']
If required, we can open and preview the image files directly from the zip file:
# extract a specific file from the zip container
# Let's grab one of the images
image_file = zip_.open(f"Items/{images[0]}")
image_file
<zipfile.ZipExtFile name='Items/_8a6712fa3ab54067a8165ef97c01bebf9d504e1d_l101_ol_figure9.jpg' mode='r' compress_type=deflate>
We can use the IPython display machinery to render the image file if we read its contents:
from IPython.display import Image
# Read the open file (a once only operation on the file pointer)
img_data = image_file.read()
# Display the image
Image(img_data)

We can also preview the image using packages such as Pillow:
import io
from PIL import Image as Image2
# If we haven't yet read the file, we can open it directly
# PIL.Image.open(image_file)
# From the raw data, create a file like object
img_fo = io.BytesIO(img_data)
# Open and render the image
Image2.open( img_fo )

Adding Images to a Database#
As a proof of concept, let’s see how we might add some images to out database, and then retrieve them again.
# Create a test database
# Give ourselves a clean slate to work with
test_db_name = "image_test.db"
!rm -f $test_db_name
db_test = Database(test_db_name)
# Create a test table in that database
db_test_table = db_test["test_table"]
# Add an image directly to that table
# An appropriate table schema will be created automatically
# Get a reference to an image file
image_file = zip_.open(f"Items/{images[0]}")
# Read the contents of the file
image_data = image_file.read()
# and add inage data to the database
db_test_table.insert({"item": image_data})
<Table test_table (item)>
We can preview the schema created for the table:
db_test_table.schema
'CREATE TABLE [test_table] (\n [item] BLOB\n)'
If we were to create our own table definition, we would set the column type to "BLOB".
We can see the image data is now in our database:
pd.read_sql("SELECT * FROM test_table", con=db_test.conn)
| item | |
|---|---|
| 0 | b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x01... |
We can also read the data out and re-display the image:
#Get the image data
img_data = pd.read_sql("SELECT * FROM test_table", con=db_test.conn).loc[0, "item"]
# Render the image using IPython display machinery
Image(img_data)
Summary#
In this section, we have seen how we can scrape a list of free OpenLearn units from a catalogue web page on the OpenLearn website and add this data to a simple, file-based database that supported full-text search over the OpenLearn unit name and OU module code.
We also saw how we could generate conventional URL paths that allowed us to download the OU-XML files associated with free OpenLearn units and add those to a database table. The XML can then be retrieved from the database and represented as an XML object that can be queried using XPATH expressions.
Finally, we demonstrated how we can download an HTML bundle associated with an OpenLearn unit as a zip archive file and programmatically inspect its contents. From the assumed “contentful” HTML files in the archive we could identify assumed “contentful” images, extract them from the archive file, preview them, store them in a simple file based database, retrieve them from the database and preview them again.